python爬虫HTTP协议剖析
”python 实现http协议 python 爬虫 python http协议“ 的搜索结果
前言 爬虫的基本原理是模拟浏览器进行 HTTP 请求,理解 HTTP 协议是写...只要大家都按照协议规定方式发起请求和返回响应结果,任何人都可以基于HTTP协议实现自己的Web客户端(浏览器、爬虫)和Web服务器(Nginx、Apach
本实战案例涉及使用Python编写一个爬虫程序,用于批量爬取B站(哔哩哔哩)上的小视频。这个案例将使用到requests库来发送HTTP请求,以及BeautifulSoup库来解析网页内容。 适用人群 Python开发者:希望提高网络爬虫...
http协议是互联网里面最重要,最基础的协议之一,我们的爬虫需要...下面这篇文章主要给大家介绍了关于python爬虫入门之快速理解HTTP协议的相关资料,文中介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧。
Python爬虫代理怎么采用HTTP协议的代理IP.docxPython爬虫代理怎么采用HTTP协议的代理IP.docxPython爬虫代理怎么采用HTTP协议的代理IP.docxPython爬虫代理怎么采用HTTP协议的代理IP.docxPython爬虫代理怎么采用HTTP...
Python爬虫基础知识.pdf 了解HTTP协议和HTML语言,理解网页的基本结构和请求过程
网络爬虫基础的一个大型思维导图,基本涵盖爬虫所需的网络知识和相关协议,总结了请求响应式的浏览器运行架构,爬虫代理,cookie,session等相关的细节

python简单实现网络爬虫
标签: python
使用requests爬虫就会失败,所以得使用httpx包 import httpx client = httpx.Client(http2=True) # 之后的使用方式和requests一样 # post result = client.post(url,json=data, headers=headers, cookies=cookies )...
requests 实现了 HTTP 协议中绝大部分功能,它提供的功能包括 Keep-Alive、连接池、Cookie持久化、内容自动解压、HTTP代理、SSL认证等很多特性,下面这篇文章主要给大家介绍了python爬虫入门中关于优雅的HTTP库...
前言 urllib、urllib2、urllib3、httplib、httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反...requests 实现了 HTTP 协议中绝大部分功能,它提供的功能包括 Keep-Alive、连接池、Cookie持久化、内容自动解
首先,我们来看一个Python抓取网页的库:urllib或urllib2。 那么urllib与urllib2有什么区别呢? 可以把urllib2当作urllib的扩增,比较明显的优势是urllib2.urlopen()可以接受Request对象作为参数,从而可以控制HTTP ...
然而,在使用Python爬虫时,我们也需要注意遵守网站的robots协议,避免对网站造成过大的访问压力,以及尊重他人的隐私和版权。 总之,Python爬虫是一种强大的数据抓取工具,可以帮助我们高效地从互联网上获取所需的...
# 大家说的Python爬虫是指什么?学会Python爬虫需要了解的五大方面 Python爬虫是一种自动化程序,它可以模拟人类在互联网上的行为,从而自动收集互联网上的信息。因此,Python爬虫在各个领域都非常有用,比如信息...
Python爬虫的实现需要用到一些常用的库,如requests、BeautifulSoup、lxml、re等。其中,requests库用于发送HTTP请求,BeautifulSoup和lxml库用于解析网页,re库用于正则表达式匹配。 在使用Python爬虫时,需要注意...
然而,在使用Python爬虫时,我们也需要注意遵守网站的robots协议,避免对网站造成过大的访问压力,以及尊重他人的隐私和版权。 总之,Python爬虫是一种强大的数据抓取工具,可以帮助我们高效地从互联网上获取所需的...

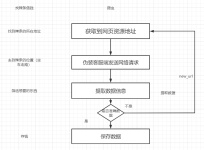
对于新手做Python爬虫来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。
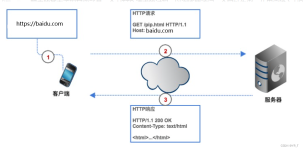
HTTP协议及Requests库HTTP协议什么是HTTP协议呢?URL网络格式Requests库HTTP协议与Requests库 HTTP协议 什么是HTTP协议呢? HTTP(Hyper Text Transfer Protocol)<超文本传输协议>的缩写.是用于从WWW服务器传输...
文章目录一.HTTP协议1. HTTP协议的框架2. HTTP协议对资源的操作3. 用户对HTTP协议的操作二.requests库的安装三.requests库的7个主要使用方法1.方法的解析2.方法的使用a....【python爬虫基础入门】系列是对p
Python爬虫的实现需要用到一些常用的库,如requests、BeautifulSoup、lxml、re等。其中,requests库用于发送HTTP请求,BeautifulSoup和lxml库用于解析网页,re库用于正则表达式匹配。 在使用Python爬虫时,需要注意...

你需要懂的技术包括Python编程语言、HTTP协议、数据库、Linux等知识。这样才能做到真正从入门python爬虫到精通,下面推荐几本经典的书籍。 Python语言入门的书籍: 适合没有编程基础的,入门Python的书籍 《简明...
2. 网络协议:爬虫需要通过网络获取数据,因此需要掌握HTTP协议、TCP/IP协议等相关知识。 3. 数据解析:获取到的网页数据需要进行解析和处理,因此需要了解一些常用的数据解析库,如BeautifulSoup、正则表达式等。 ...
python爬虫常见面试题之http协议问题总结.pdf

推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地